Benchmark Process
- From the census extract the total number of people by DAM2
total_pp <- readRDS(file = "Recursos/04_FH_Arcosin/06_censo_mrp.rds") %>%
mutate(dam = substr(dam2,1,2))
N_dam_pp <- total_pp %>% group_by(dam,dam2) %>%
summarise(total_pp = sum(n) ) %>%
group_by(dam) %>% mutate(dam_pp = sum(total_pp))
tba(N_dam_pp %>% data.frame() %>% slice(1:10))
|
dam
|
dam2
|
total_pp
|
dam_pp
|
|
01
|
0101
|
35750
|
88799
|
|
01
|
0102
|
26458
|
88799
|
|
01
|
0103
|
26591
|
88799
|
|
02
|
0201
|
58937
|
573065
|
|
02
|
0202
|
43700
|
573065
|
|
02
|
0203
|
35309
|
573065
|
|
02
|
0204
|
47230
|
573065
|
|
02
|
0205
|
35694
|
573065
|
|
02
|
0206
|
38832
|
573065
|
|
02
|
0207
|
42103
|
573065
|
- Obtaining direct estimates by DAM or the level of aggregation at which the survey is representative.
In this code, an RDS file of a survey (07_data_JAM.rds) is read, and the transmute() function is used to select and transform the variables of interest.
encuesta <- readRDS("Recursos/04_FH_Arcosin/07_encuesta.rds") %>%
mutate(dam = substr(dam2,1,2))
The code is conducting survey data analysis using the survey package in R. Initially, an object design is created as a survey design using the as_survey_design() function from the srvyr package. This design includes primary sampling unit identifiers (upm), weights (fep), strata (estrato), and survey data (encuesta). Subsequently, the design object is grouped by the variable “Aggregate,” and the mean of the variable “pobreza” with a confidence interval for the entire population is calculated using the survey_mean() function. The result is stored in the directoDam object and displayed in a table.
library(survey)
library(srvyr)
options(survey.lonely.psu = "adjust")
diseno <-
as_survey_design(
ids = upm,
weights = fep,
strata = estrato,
nest = TRUE,
.data = encuesta
)
directoDam <- diseno %>%
group_by(dam) %>%
summarise(
theta_dir = survey_mean(pobreza, vartype = c("ci"))
)
tba(directoDam %>% slice(1:10))
|
dam
|
theta_dir
|
theta_dir_low
|
theta_dir_upp
|
|
01
|
0.9926
|
0.9848
|
1.0004
|
|
02
|
0.9760
|
0.9638
|
0.9881
|
|
03
|
0.9191
|
0.8566
|
0.9816
|
|
04
|
0.8160
|
0.7742
|
0.8578
|
|
05
|
0.7486
|
0.6943
|
0.8029
|
|
06
|
0.9419
|
0.8993
|
0.9844
|
|
07
|
0.8019
|
0.7076
|
0.8962
|
|
08
|
0.5933
|
0.4904
|
0.6961
|
|
09
|
0.8628
|
0.8167
|
0.9090
|
|
10
|
0.7379
|
0.6348
|
0.8410
|
- Carry out the consolidation of information obtained in 1 and 2.
temp <- estimacionesPre %>%
inner_join(N_dam_pp ) %>%
inner_join(directoDam )
tba(temp %>% slice(1:10))
|
dam2
|
theta_pred
|
dam
|
total_pp
|
dam_pp
|
theta_dir
|
theta_dir_low
|
theta_dir_upp
|
|
0102
|
0.9832
|
01
|
26458
|
88799
|
0.9926
|
0.9848
|
1.0004
|
|
0103
|
0.8759
|
01
|
26591
|
88799
|
0.9926
|
0.9848
|
1.0004
|
|
0202
|
0.9391
|
02
|
43700
|
573065
|
0.9760
|
0.9638
|
0.9881
|
|
0203
|
0.8117
|
02
|
35309
|
573065
|
0.9760
|
0.9638
|
0.9881
|
|
0205
|
0.9645
|
02
|
35694
|
573065
|
0.9760
|
0.9638
|
0.9881
|
|
0212
|
0.8303
|
02
|
58509
|
573065
|
0.9760
|
0.9638
|
0.9881
|
|
0301
|
0.9419
|
03
|
41762
|
93896
|
0.9191
|
0.8566
|
0.9816
|
|
0302
|
0.9109
|
03
|
52134
|
93896
|
0.9191
|
0.8566
|
0.9816
|
|
0401
|
0.8079
|
04
|
49909
|
81732
|
0.8160
|
0.7742
|
0.8578
|
|
0402
|
0.8307
|
04
|
31823
|
81732
|
0.8160
|
0.7742
|
0.8578
|
- With the organized information, calculate the weights for the Benchmark
R_dam2 <- temp %>% group_by(dam) %>%
summarise(
R_dam_RB = unique(theta_dir) / sum((total_pp / dam_pp) * theta_pred)
) %>%
left_join(directoDam, by = "dam")
tba(R_dam2 %>% arrange(desc(R_dam_RB)))
|
dam
|
R_dam_RB
|
theta_dir
|
theta_dir_low
|
theta_dir_upp
|
|
13
|
1.1793
|
0.6461
|
0.5226
|
0.7696
|
|
02
|
1.1158
|
0.9760
|
0.9638
|
0.9881
|
|
01
|
1.0996
|
0.9926
|
0.9848
|
1.0004
|
|
09
|
1.0669
|
0.8628
|
0.8167
|
0.9090
|
|
14
|
1.0550
|
0.8792
|
0.8376
|
0.9207
|
|
10
|
1.0465
|
0.7379
|
0.6348
|
0.8410
|
|
05
|
1.0098
|
0.7486
|
0.6943
|
0.8029
|
|
06
|
1.0031
|
0.9419
|
0.8993
|
0.9844
|
|
04
|
0.9991
|
0.8160
|
0.7742
|
0.8578
|
|
08
|
0.9973
|
0.5933
|
0.4904
|
0.6961
|
|
03
|
0.9940
|
0.9191
|
0.8566
|
0.9816
|
|
07
|
0.9474
|
0.8019
|
0.7076
|
0.8962
|
|
11
|
0.8631
|
0.4277
|
0.3056
|
0.5498
|
|
12
|
0.0480
|
0.0292
|
0.0120
|
0.0463
|
calculating the weights for each domain.
pesos <- temp %>%
mutate(W_i = total_pp / dam_pp) %>%
select(dam2, W_i)
tba(pesos %>% slice(1:10))
|
dam2
|
W_i
|
|
0102
|
0.2980
|
|
0103
|
0.2995
|
|
0202
|
0.0763
|
|
0203
|
0.0616
|
|
0205
|
0.0623
|
|
0212
|
0.1021
|
|
0301
|
0.4448
|
|
0302
|
0.5552
|
|
0401
|
0.6106
|
|
0402
|
0.3894
|
- Perform FH Benchmark Estimation
estimacionesBench <- estimacionesPre %>%
left_join(R_dam2, by = c("dam")) %>%
mutate(theta_pred_RBench = R_dam_RB * theta_pred) %>%
left_join(pesos) %>%
select(dam, dam2, W_i, theta_pred, theta_pred_RBench)
tba(estimacionesBench %>% slice(1:10))
|
dam
|
dam2
|
W_i
|
theta_pred
|
theta_pred_RBench
|
|
01
|
0102
|
0.2980
|
0.9832
|
1.0811
|
|
01
|
0103
|
0.2995
|
0.8759
|
0.9632
|
|
02
|
0202
|
0.0763
|
0.9391
|
1.0478
|
|
02
|
0203
|
0.0616
|
0.8117
|
0.9057
|
|
02
|
0205
|
0.0623
|
0.9645
|
1.0762
|
|
02
|
0212
|
0.1021
|
0.8303
|
0.9264
|
|
03
|
0301
|
0.4448
|
0.9419
|
0.9363
|
|
03
|
0302
|
0.5552
|
0.9109
|
0.9054
|
|
04
|
0401
|
0.6106
|
0.8079
|
0.8072
|
|
04
|
0402
|
0.3894
|
0.8307
|
0.8299
|
- Validation: FH Estimation with Benchmark
estimacionesBench %>% group_by(dam) %>%
summarise(theta_reg_RB = sum(W_i * theta_pred_RBench)) %>%
left_join(directoDam, by = "dam") %>%
tba()
|
dam
|
theta_reg_RB
|
theta_dir
|
theta_dir_low
|
theta_dir_upp
|
|
01
|
0.9926
|
0.9926
|
0.9848
|
1.0004
|
|
02
|
0.9760
|
0.9760
|
0.9638
|
0.9881
|
|
03
|
0.9191
|
0.9191
|
0.8566
|
0.9816
|
|
04
|
0.8160
|
0.8160
|
0.7742
|
0.8578
|
|
05
|
0.7486
|
0.7486
|
0.6943
|
0.8029
|
|
06
|
0.9419
|
0.9419
|
0.8993
|
0.9844
|
|
07
|
0.8019
|
0.8019
|
0.7076
|
0.8962
|
|
08
|
0.5933
|
0.5933
|
0.4904
|
0.6961
|
|
09
|
0.8628
|
0.8628
|
0.8167
|
0.9090
|
|
10
|
0.7379
|
0.7379
|
0.6348
|
0.8410
|
|
11
|
0.4277
|
0.4277
|
0.3056
|
0.5498
|
|
12
|
0.0292
|
0.0292
|
0.0120
|
0.0463
|
|
13
|
0.6461
|
0.6461
|
0.5226
|
0.7696
|
|
14
|
0.8792
|
0.8792
|
0.8376
|
0.9207
|
Results Validation
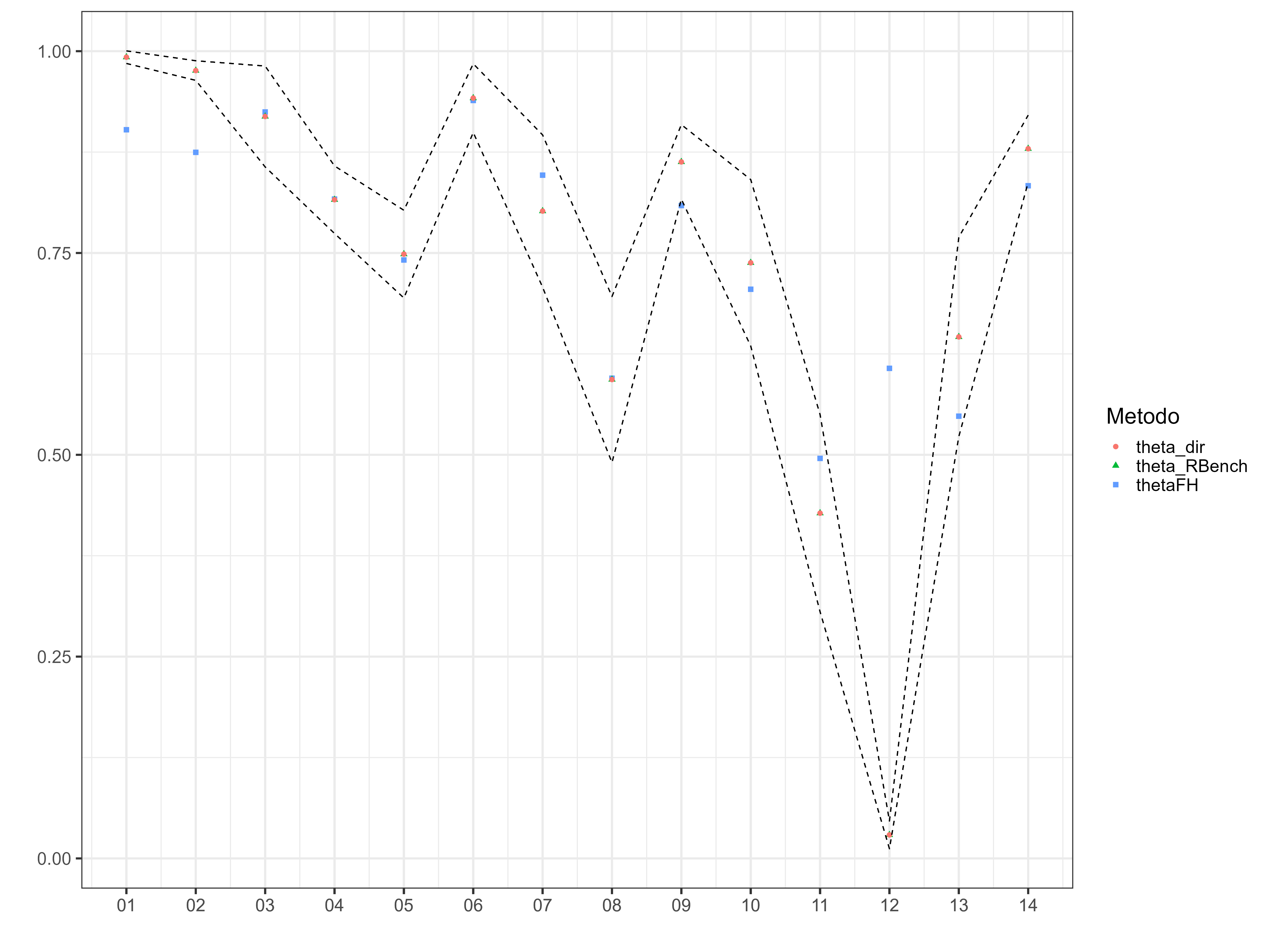
This code conducts data analysis and visualization using the ggplot2 library. Specifically, it merges two data frames using the left_join() function, groups the data by the dam variable, and performs some operations to transform the thetaFH and theta_pred_RBench variables. Afterwards, it utilizes the gather() function to organize the data in a long format and visualizes it with ggplot().
The resulting visualization displays points in different shapes and colors, representing various estimation methods. Additionally, it includes two dashed lines that depict the upper and lower confidence intervals for the observed values in the theta_dir variable.
temp <- estimacionesBench %>% left_join(
bind_rows(
data_dir %>% select(dam2, thetaFH = pred_arcoseno),
data_syn %>% select(dam2, thetaFH = pred_arcoseno))) %>%
group_by(dam) %>%
summarise(thetaFH = sum(W_i * theta_pred),
theta_RBench = sum(W_i * theta_pred_RBench)
) %>%
left_join(directoDam, by = "dam") %>%
mutate(id = 1:n())
temp %<>% gather(key = "Metodo",value = "Estimacion",
-id, -dam, -theta_dir_upp, -theta_dir_low)
p1 <- ggplot(data = temp, aes(x = id, y = Estimacion, shape = Metodo)) +
geom_point(aes(color = Metodo), size = 2) +
geom_line(aes(y = theta_dir_low), linetype = 2) +
geom_line(aes(y = theta_dir_upp), linetype = 2) +
theme_bw(20) +
scale_x_continuous(breaks = temp$id,
labels = temp$dam) +
labs(y = "", x = "")
# ggsave(plot = p1,
# filename = "Recursos/04_FH_Arcosin/08_validar_bench.png",width = 16,height = 12)
p1